I’m thrilled to announce the release of my newest book, Intrusion Detection Honeypots: Detection through…
Author: Chris Sanders

In an essay I published earlier today, I spoke about the recurring debate in information…

Should security researchers release offensive security tools (OSTs)? Industry insiders and outsiders have debated the…
Most cyber security educators are practitioners first and educators second. While this model ensures learners…

Each December I like to reflect on the best things I’ve read over the course…
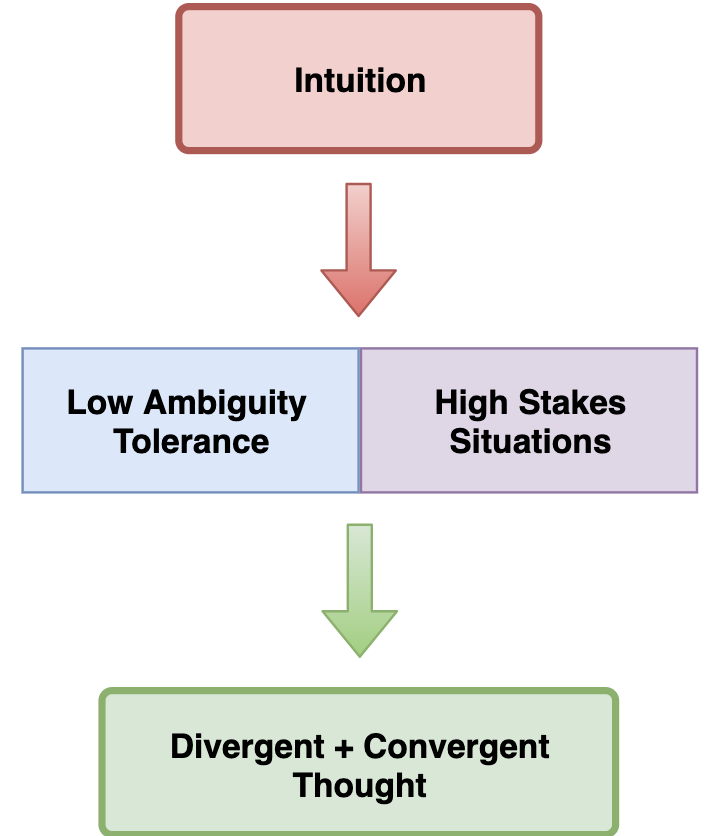
Creative Choices: Developing a Theory of Divergence, Convergence, and Intuition in Security Analysts
Humans lie at the heart of security investigations, but there is an insufficient amount of…

The typical answer to someone who asks how they can break into information security is,…

Unwritten social contracts dictate many of the rules of modern employment between the employer and…

I’ve argued for some time that information security is in a growing state of cognitive…

I’m glad to share the Practical Threat Hunting training course with you. I created this…