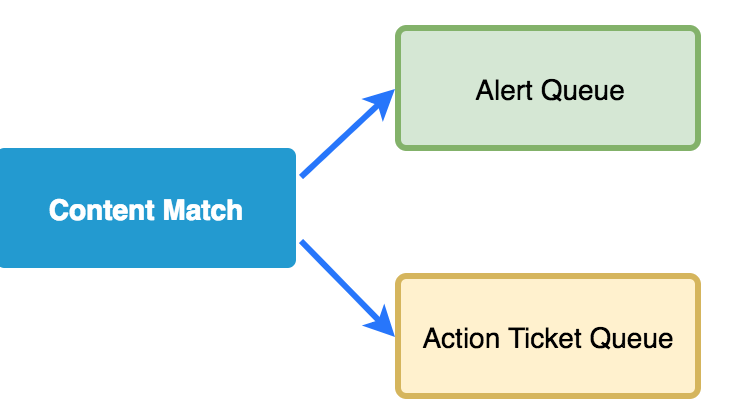
A simple content match provides the launching point for many of our investigations. You write…
Information Security Analyst, Author, and Instructor
A simple content match provides the launching point for many of our investigations. You write…
I’ve been a Security Onion user for a long time and recommend it to people…
SANS recently released the results of their SOC survey that was put together by Chris…
I’ve struggled for a long time to find a case management system that I thought…
I worked in security operation centers for a long time, and I really grew to…
Building a security lab is something I get asked about really often. So often, in…
One of the problems we face while trying to detect and respond to adversaries is…
Being a native Kentuckian, it’s no secret that I bleed blue. As I write this, my…
Whenever I get the chance I like to try and extract lessons from practitioners in…
I recently spoke at a Charleston ISSA meeting about using honeypots as an effective part…