In September of this year, I successfully defended my doctoral dissertation, earning the title of…
Category: Investigations
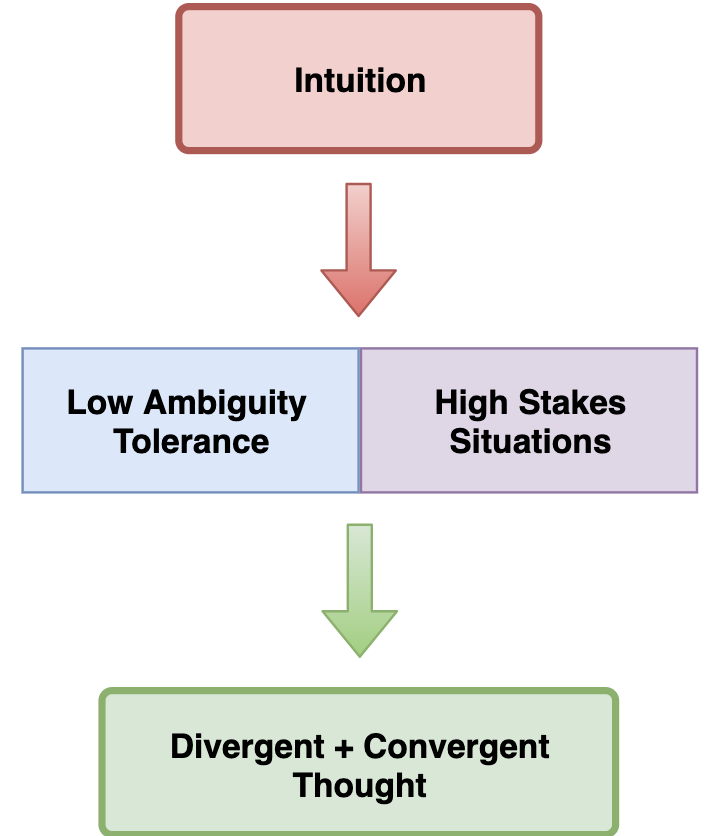
Creative Choices: Developing a Theory of Divergence, Convergence, and Intuition in Security Analysts
Humans lie at the heart of security investigations, but there is an insufficient amount of…

I’ve argued for some time that information security is in a growing state of cognitive…
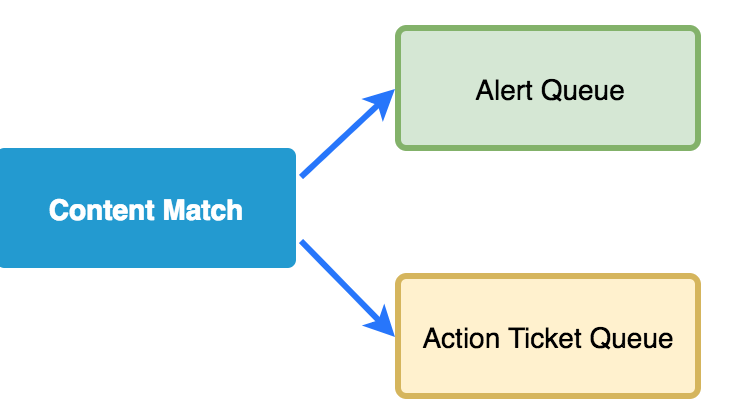
A simple content match provides the launching point for many of our investigations. You write…
As an analyst acquires experience investigating threats they will naturally gain mastery of evidence. This…
SANS recently released the results of their SOC survey that was put together by Chris…
This is part three in the Know your Bias series where I examine a specific type…
I’ve struggled for a long time to find a case management system that I thought…
In the first part of this series I told a personal story to illustrated the components…
In this blog series I’m going to dissect cognitive biases and how they relate to…